Crypto Beginner Series EP 8: What is a Merkle Tree
We are well into the Crypto Beginner Series and it is time we start looking into the details of what makes up a blockchain. It is one thing to invest in cryptocurrency and blockchain technology. But it is another to fully understand the details of how blockchain works.
In many blockchains, one piece of technology that is being incorporated into the network is the Merkle Tree. Although there are many parts to this network, the Merkle Tree is one important aspect to understand when identifying how we plan to ensure efficiency and reliability in the verification process.

History
The Merkle Tree is not some new amazing discovery. It is a tested and true system that is used quite widely not just in blockchain, but any trust-less or peer-2-peer environment. In fact, this concept dates back to 1979, before blockchain was even an idea. It is named after computer scientist, Ralph Merkle.
A Merkle Tree, in simple terms, takes lots of data and compresses it down into one simple string of characters. This string can prove the verity of the data held within, without revealing what that data is. Similar to a compressed file (.ZIP or .RAR), if named correctly according to a certain standard, a user can recognize the content without having to decompress and open the contained files. This string of characters (title) is called a hash. Hashing is a one-way function. If you put in the same data you will always get the same hash, but you cannot take that hash and extract the original data.
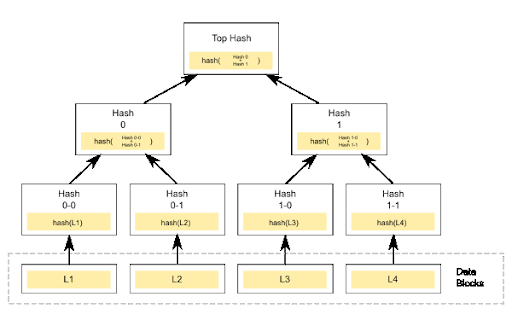
A Tree
The ‘tree’ concept is a common idea throughout science. It refers to a structure that includes parents and children branching off each other. In this case, it is an upside-down tree in the sense that you start with all the leaves (Transactions/blocks). You then work back to the one parent hash (Merkle Root). As seen above, we start with transactions that get hashed twice before they get included in the Merkle Tree. We might have transactions 1–100 hashed into block L1, 101–200 hashed into block L2, 201–300 into block L3, 301–400 into block L4. These are then hashed into the bottom branch of the tree. For example, block L1 is hashed into hash 0–0.
This diagram shows what we call a binary tree. This means that each parent can have two children branches maximum. Technically, you can increase this but binary trees are the most common. Once we have Hash 0–0 and 0–1, this gets hashed into its ‘parent’ hash (Hash 0). This is continued until we get to the top hash which is called the Merkle Root.
Benefits
This process has multiple benefits including security, speed, and efficiency. By using this process to condense data, it can be verified very quickly without revealing any actual data by matching up each hash with the Merkle Tree Root. Due to the complexity of the Merkle Tree created in correlation with the decentralized aspect of blockchain, it makes it very difficult to alter the data found within these hashes.
The speed of a network can be increased simply by using this technology. Instead of sending files over the network to be verified and then sent back, one computer only needs to send the hash. Remember this is only a string of characters, so it can be very quickly verified. If there is a discrepancy, then hashes of the subtrees are requested until the culpable block is found and altered as necessary. This is much faster than searching an entire file for one error. Of course, this is also a much more efficient use of resources.